AxisGuide
*Equal contribution · †Co-corresponding authors
Do Visuomotor Manipulation Policies "Understand" Actions?

Generalization requires grounding the robot action coordinate system in RGB observations. Yet current visuomotor policies can memorize image-action correspondences instead, leading to poor generalization when the target moves to unseen locations.
Why does this happen?
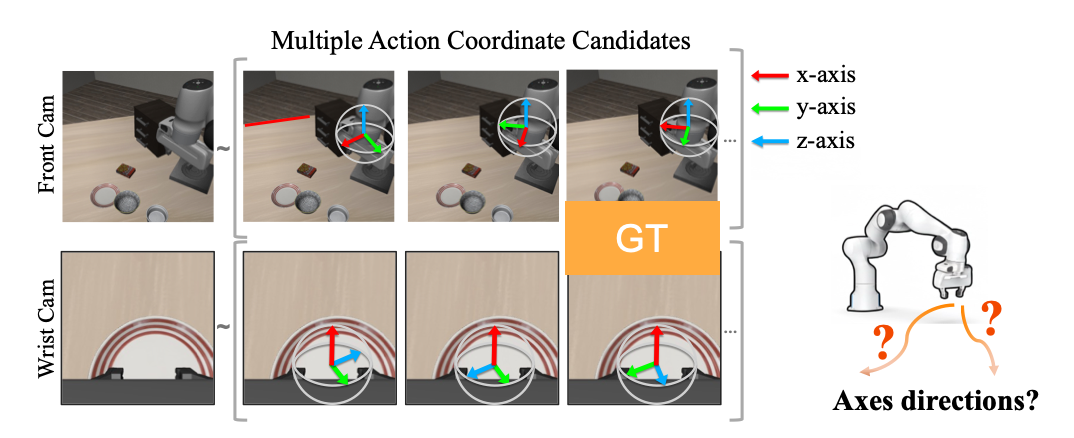
Standard RGB observations provide no explicit visual anchor for +x, +y, and +z robot actions. The robot base is the only reference, but it is often visually ambiguous, occluded, or outside the camera view, making action-coordinate grounding difficult.
Motivation
Current visuomotor policies often understand what to do, but struggle with how to execute the correct low-level action. In robot manipulation, actions are usually defined in the robot base frame, while observations are RGB images. Without an explicit visual reference, the policy must infer how base-frame motions such as +x, +y, and +z appear in the image.
Conventional Policy
Learns image-to-action correspondences implicitly and can fail when the target object moves to unseen locations.
AxisGuide
Provides explicit image-space cues for the robot action coordinate system, improving action grounding and generalization.
Method Overview
Given camera intrinsics, extrinsics, and the end-effector pose, AxisGuide projects unit robot base-frame translations onto the image plane. The projected +x, +y, and +z directions are rendered as cue channels and concatenated with RGB observations. This keeps the original RGB image intact while giving the policy a clean visual reference for action-coordinate semantics.
Key Results
AxisGuide improves success from 52.38% to 65.71% in simulation.
AxisGuide improves success from 30.12% to 50.00% on the Pick Up (Pear) task.
AxisGuide adds only about 0.005 seconds of latency per inference on SmolVLA.
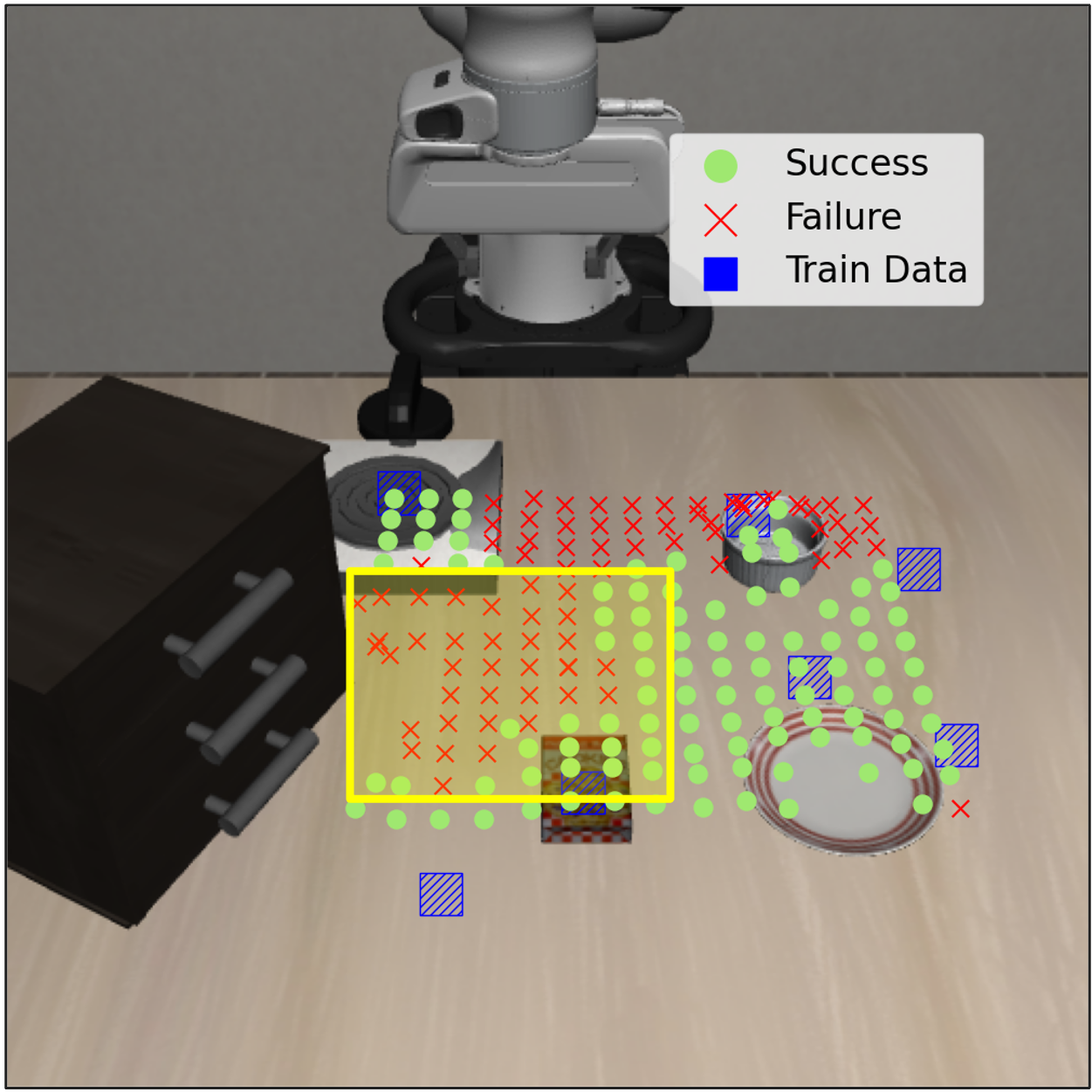
Novel Object Locations in Simulation
Models trained with AxisGuide reliably reach object positions between training clusters, suggesting that explicit coordinate cues help the policy adjust end-effector motion under distribution shift.








Novel Object Locations in the Real World
In the same experimental setup, explicit coordinate grounding improves task success under unseen real-world object locations. Wrist-view clips are shown alongside the front camera because multi-view control benefits from consistent action-coordinate cues across views.
Baseline
AxisGuide
Real-World Manipulation Tasks
With 50 demonstrations per task, AxisGuide supports reliable execution across diverse behaviors including closing a pot, flipping a pot, and pick-and-place manipulation.
Close Pot
Flip Pot
Pick & Place Grape
Multi-Task Performance
As task diversity increases, a single language-conditioned policy must ground action coordinates across many object configurations and instructions. AxisGuide preserves this coordinate grounding at the suite level, improving robust instruction-conditioned execution in multi-view settings.
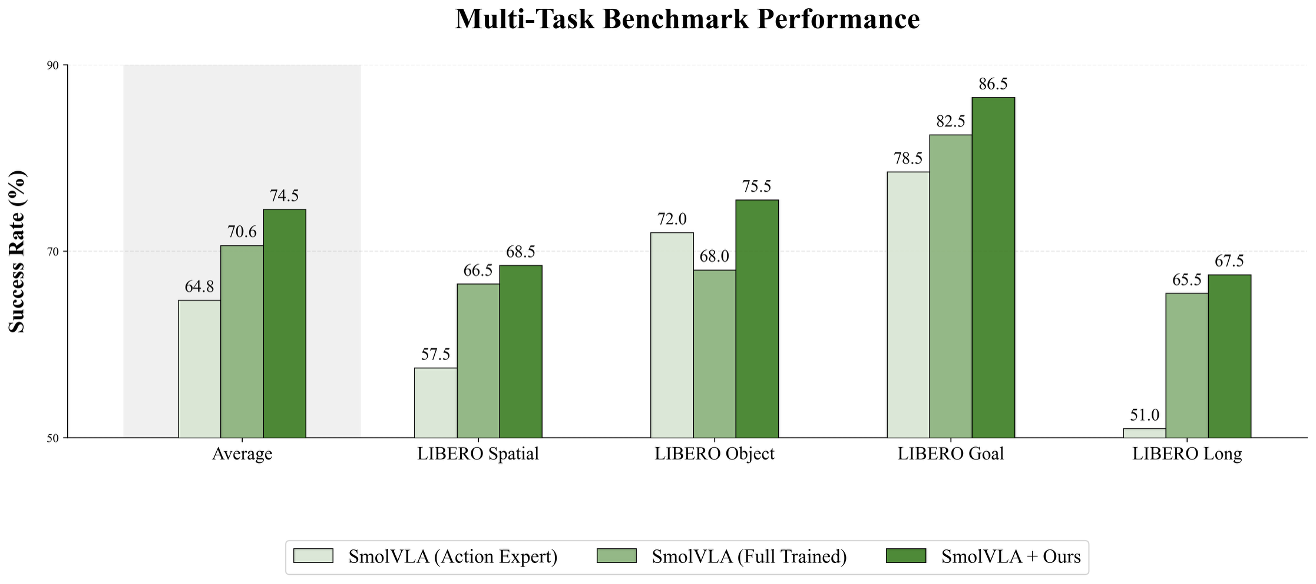
LIBERO Spatial




LIBERO Object
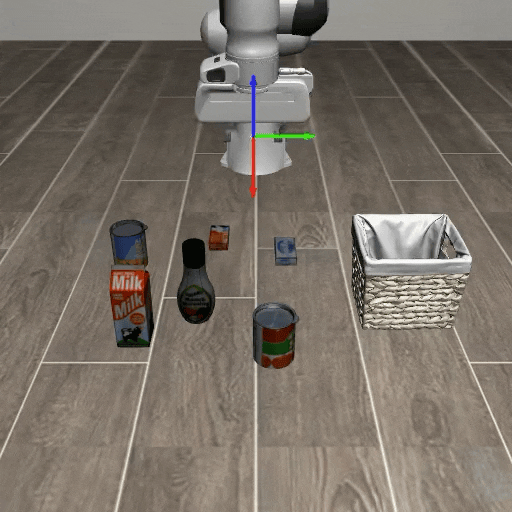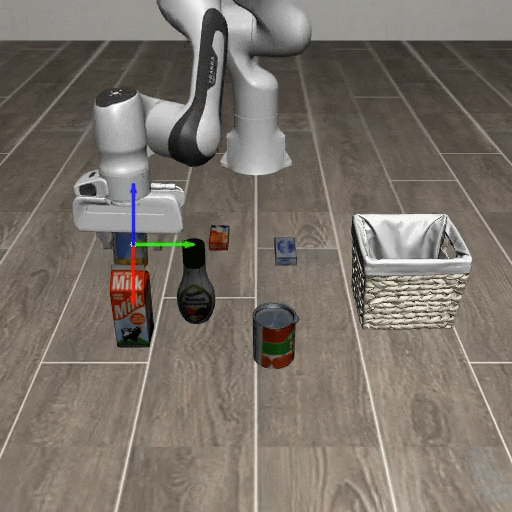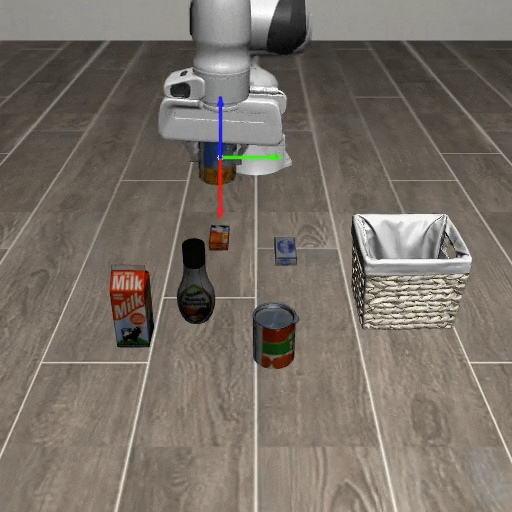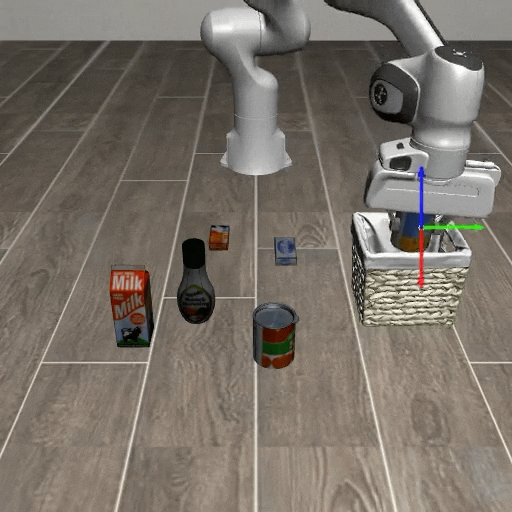



Comparison with Visual Cue Baselines
Existing visual cue methods provide spatial or temporal guidance, but they do not explicitly represent the robot action coordinate system. AxisGuide directly shows where the x, y, and z action directions lie in the image, enabling the policy to infer how to move toward a target under novel object positions.
52.38%
51.90%
52.38%
65.71%
BibTeX
@inproceedings{jang2026axisguide,
title = {AxisGuide: Grounding Robot Action Coordinate System in RGB Observations for Robust Visuomotor Manipulation},
author = {Jang, Jiyun and Sung, Yujin and Joung, Woosung and Chae, Daewon and Lee, Sangwon and Kim, Sohwi and Kim, Jinkyu and Lee, Jungbeom},
booktitle = {Robotics: Science and Systems},
year = {2026}
}